
Custom Allocators in C
Memory allocation is not fun, specially in C. Even if the lack of fat pointers is
ignored, every single allocation needs to be kept in my small brain in order to be
cleaned-up later. And don’t forget, only a single free can bring balance to the
program, no more, no less.
No wonder languages with garbage collectors are so popular. Makes it all so easy.
There are times however that a GC is definitely an overkill, or even simply impossible. But why would that be?
First, sometimes your language does not support one (like C), and it is not viable to change to a language that has one. A GC brings a runtime with it, and most of the time it is not small. If you are developing for WASM or embedded, code size is important and needs to be taken into account.
The second reason, and often the one that prevails, is speed.
In applications that require high performance, having a GC pausing the code to run will ruin your day. Think of a game engine, where you are fighting for that frame rate, or a trading system, where being slower will lose you money. Memory allocation is not fast, even when manual, so controlling when it happens becomes the deciding factor.
But then are we going back to malloc and free? Of course not, there are much
better ways to handle allocation, depending on when and how you intend to use the
memory. This is the realm of custom-built allocators.
Linear allocators
This is as simple as an allocator can get. You have a buffer of bytes and each allocation request is just an offset into it.
#define BUFFER_SIZE 1024
uint8_t buffer[BUFFER_SIZE];
size_t head = 0;
void* allocate(size_t size) {
void* mem = &buffer[head];
head += size;
if (head > BUFFER_SIZE) {
return NULL;
}
return mem;
}
And that’s it. When allocate() is called, we return a chunk of memory and
increment past it for the next call. If there is not enough space in the buffer,
we return NULL.
We can then use our freshly baked allocator like this:
int main(void) {
int *data = allocate(12 * sizeof(*data));
if (!data) {
perror("allocate");
return EXIT_FAILURE;
}
printf("buffer=%p, data=%p, head=%zu\n", buffer, data, head);
// stdout: buffer=0x6468babc4040, data=0x6468babc4040, head=48
data = allocate(32 * sizeof(*data));
if (!data) {
perror("allocate");
return EXIT_FAILURE;
}
printf("buffer=%p, data=%p, head=%zu\n", buffer, data, head);
// stdout: buffer=0x6468babc4040, data=0x6468babc4070, head=176
return EXIT_SUCCESS;
}
In this example, the memory looks like this:
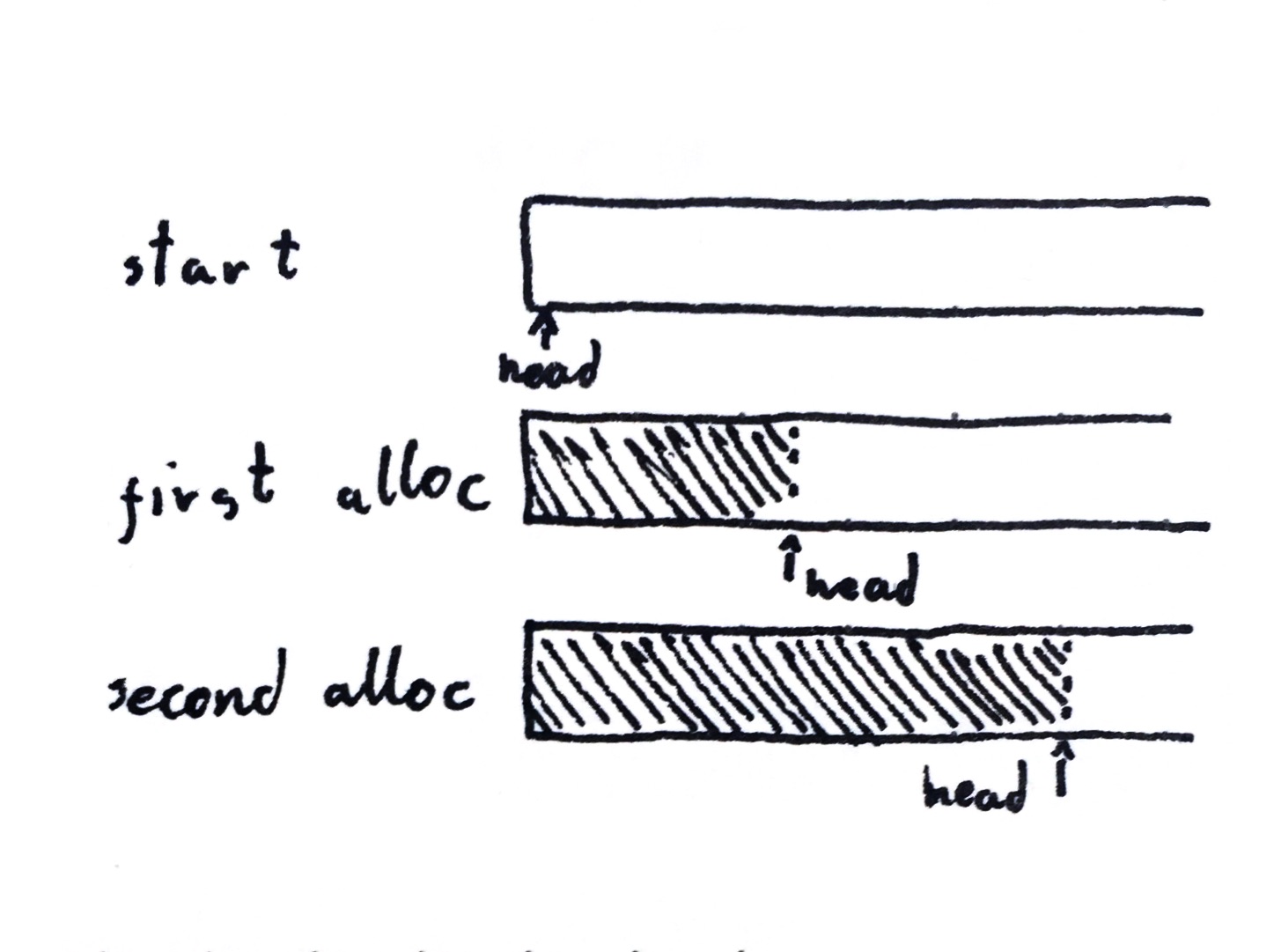
Now you might ask: where is the free? And this is where the first big difference from the standard allocators enters the scene. There is no free. Or at least not one for each of the allocations.
You see, the linear allocator is exactly that: linear. Allocations are done sequentially without holes and zero metadata. That means we have no way of knowing where each allocation starts and ends, and no way of creating holes for reuse.
“Then what is the use for this allocator?” you ask. Well, there is a pattern that most allocations share: they are done in groups. Most of the time we don’t have single allocations with individual lifetimes, we have many allocations that share a single lifetime. Consider an HTTP server, it needs to perform many allocations during the request lifecycle, but all of them are bound by a single lifetime: the request. In a game engine, many allocations are performed, but a considerable amount will not be used past the end of the frame.
A linear allocator takes advantage of that and groups all allocations done through it to a single lifetime. Then, when it expires, we free all the allocations in sweet constant time:
void reset(void) {
head = 0;
}
By setting a single variable, the entire buffer is free again. This not only fast for the computer, but also reduces the mental burden placed upon the developer.
Now, we shall name this a Fixed Buffer Allocator (or FBA) before giving it a proper implementation, because yes, although the above works, it has some big flaws. Big enough to make it unusable.
Memory Alignment
Computers have a harsh limitation on how memory can be accessed: the address of the accessed memory needs to be aligned to its integer size.
But what does that mean?
When the processor requests to read or write an integer of some size, the address of where it is placed needs to be a multiple of its size. So a 4 byte integer can only be loaded or stored in an address that is a multiple of 4, a 2 byte integer can only be loaded or stored in an even address, and so on and so forth.

This means that our current implementation, simply bumping the head forward (this is where the other name for this allocator, Bump Allocator, comes from) will produce unaligned allocations:
short* a = allocate(sizeof(*a));
int* b = allocate(sizeof(*b)); // unaligned!
To fix this, we need to round up our allocation head to the next multiple of the desired alignment.
View this stack overflow answer (to a completely unrelated question) for a good explanation of how the rounding happens. It explains the topic better than me.
#define ALIGN_TO(_value, _alignment) \
((_value) + ((_alignment) - 1) & -(_alignment))
The macro above will perform the alignment for us, so that ALIGN_TO(2, 4) will
be 4, ALIGN_TO(9, 8) will be 16, etc.
A proper implementation
Armed with such knowledge, we can create a complete implementation for a very simple, very fast, fixed buffer allocator:
// fba.h
#include <stddef.h>
#include <stdint.h>
// Align up the given integer to the given alignment.
#define ALIGN_TO(_value, _alignment) \
((_value) + ((_alignment) - 1) & -(_alignment))
// A Fixed Buffer Allocator.
//
// We store a buffer (start and end) and the current allocation head.
typedef struct fba {
uint8_t *buffer;
uint8_t *buffer_end;
uint8_t *head;
} fba_t;
// Initialize the fba to a given buffer.
static inline void fba_init(fba_t *fba, uint8_t *buffer, size_t buffer_size) {
*fba = (fba_t){
.buffer = buffer, .buffer_end = buffer + buffer_size, .head = buffer};
}
// Clear all allocations in the buffer.
static inline void fba_reset(fba_t *fba) { fba->head = fba->buffer; }
// Allocate `size` bytes with `align` alignment.
static inline void *fba_alloc_opt(fba_t *fba, size_t size, size_t align) {
// get the head, aligned correctly and check if we have enough space
uint8_t *head = (uint8_t *)ALIGN_TO((uintptr_t)fba->head, align);
if (head + size > fba->buffer_end) {
return NULL;
}
// move the head forward and return
fba->head = head + size;
return head;
}
// Allocate `size` bytes with alignment large enough for any value.
static inline void *fba_alloc(fba_t *fba, size_t size) {
return fba_alloc_opt(fba, size, _Alignof(void *));
}
You will notice that the implementation changed slightly from the first explanation.
The size was changed to a pointer to the end of the buffer and head also became
pointer. You should not be afraid of pointers, as most of the time they make the
code more concise (and faster as a bonus).
In my opinion, storing the buffer start and end is easier to understand, as we are dealing with a memory region and don’t really use it as an array in any point. When allocating, we check if the allocation head, now also a pointer, is located in the region.
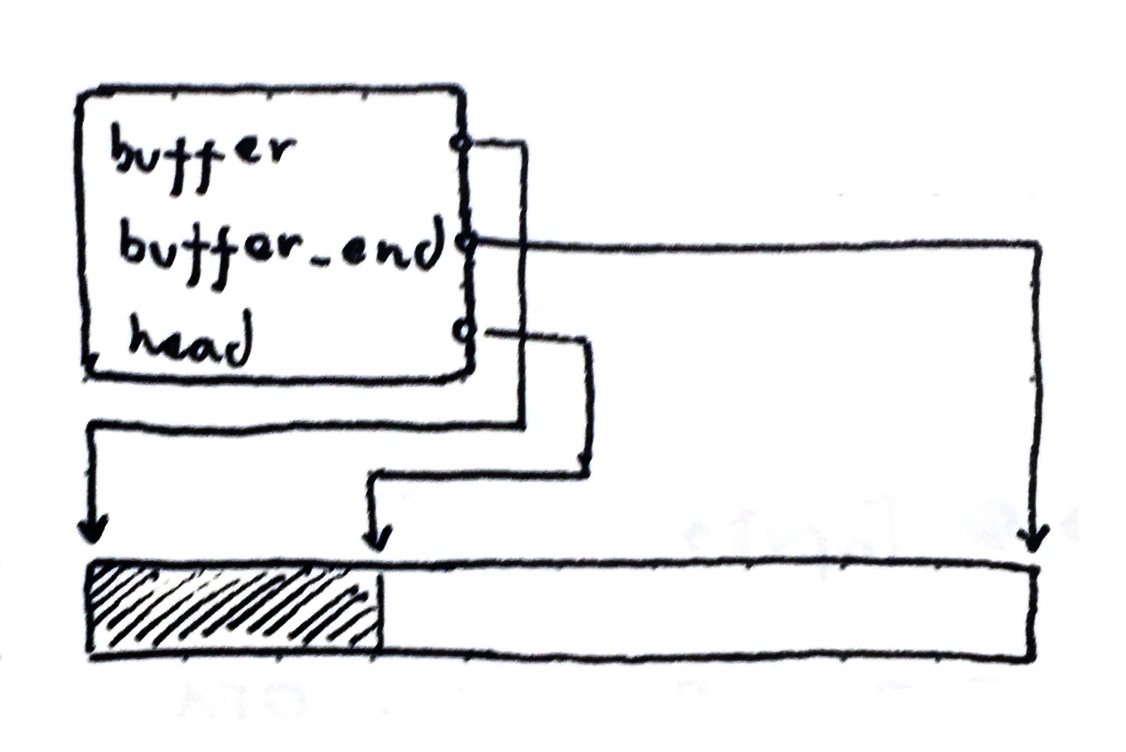
But finally, we can now use our allocator:
#include <stdarg.h>
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include "fba.h"
#define BUFFER_SIZE 1024
int main() {
// create a static buffer for our allocations. It is important to say that if
// we wanted, this buffer could be dynamically allocated by another allocator
// (like `malloc`). We just need the bytes, it does not matter where they came
// from.
static uint8_t buffer[BUFFER_SIZE];
// create an instance of our allocator. As it's state is contained in the
// struct, we could have as many of these as we want.
fba_t fba = {};
fba_init(&fba, buffer, BUFFER_SIZE);
// allocate an integer
int *v = fba_alloc_opt(&fba, sizeof(*v), _Alignof(*v));
if (!v) {
perror("fba_alloc_opt");
return EXIT_FAILURE;
}
// allocate a struct
struct {
int a;
int b;
} *s = fba_alloc_opt(&fba, sizeof(*s), _Alignof(*s));
// allocate a string
char *str = fba_alloc_opt(&fba, 32, _Alignof(char));
// clear all allocations. v, s and str now point to invalid memory
fba_reset(&fba);
return EXIT_SUCCESS;
}
We can even have some fun with it, ever wanted easy strings in C?
static char *fba_vsprintf(fba_t *fba, char const *format, va_list args) {
va_list args2;
va_copy(args2, args);
int n = vsnprintf(NULL, 0, format, args);
char *buf = fba_alloc_opt(fba, n + 1, _Alignof(char));
if (buf) {
vsnprintf(buf, n + 1, format, args2);
}
va_end(args2);
return buf;
}
static char *fba_sprintf(fba_t *fba, char const *format, ...) {
va_list args;
va_start(args, format);
char *s = fba_vsprintf(fba, format, args);
va_end(args);
return s;
}
int main() {
char *hello = fba_sprintf(&fba, "Hello, %s!", "world");
if (!hello) {
perror("fba_alloc_opt");
return EXIT_FAILURE;
}
printf("%s\n", hello);
// stdout: Hello, World!
return EXIT_SUCCESS;
}
There is, however, an issue. We need to know what will be the peek memory usage beforehand, as the size of the buffer is fixed. When we desire to cap memory usage (like in an embedded device) this is excellent, but it is not very good in a more general use case. This is where a more advanced linear allocator is required.
Arena Allocators
We want the speed and ease of use of the FBA, but also not worry about what the peak usage will be. This can be solved by moving the buffer management inside the allocator itself.
The first big change in the implementation comes from the fact that our backing buffers need to be allocated dynamically, and that raises the question: how to allocate them? This introduces another concept that is usually present when custom allocators are at play: nested allocators.
The arena allocator needs a backing allocator to allocate more space from, and it
can be any kind of allocator (although some algorithms will obviously perform
better than others). For now, we will simply use malloc to keep the examples simple.
So let’s begin with the types:
typedef struct arena_block {
struct arena_block *next;
uint8_t *buffer_end;
uint8_t *head;
uint8_t buffer[];
} arena_block_t;
typedef struct arena {
arena_block_t *blocks;
} arena_t;
There are now two data types at play: the main state arena_t that the public
API will interact with and the state for each live allocation block
(arena_block_t). Now wait a minute! What is a block?
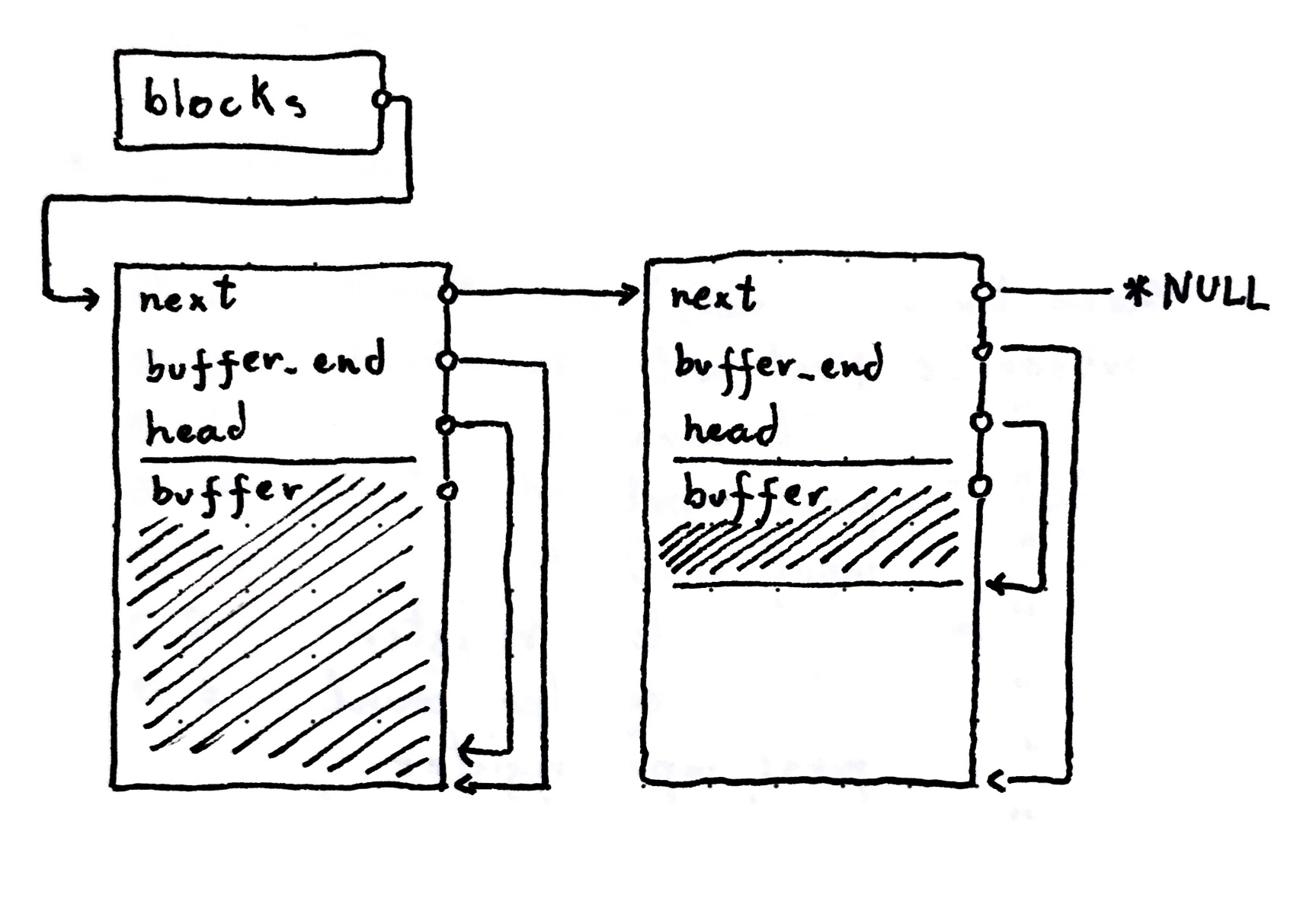
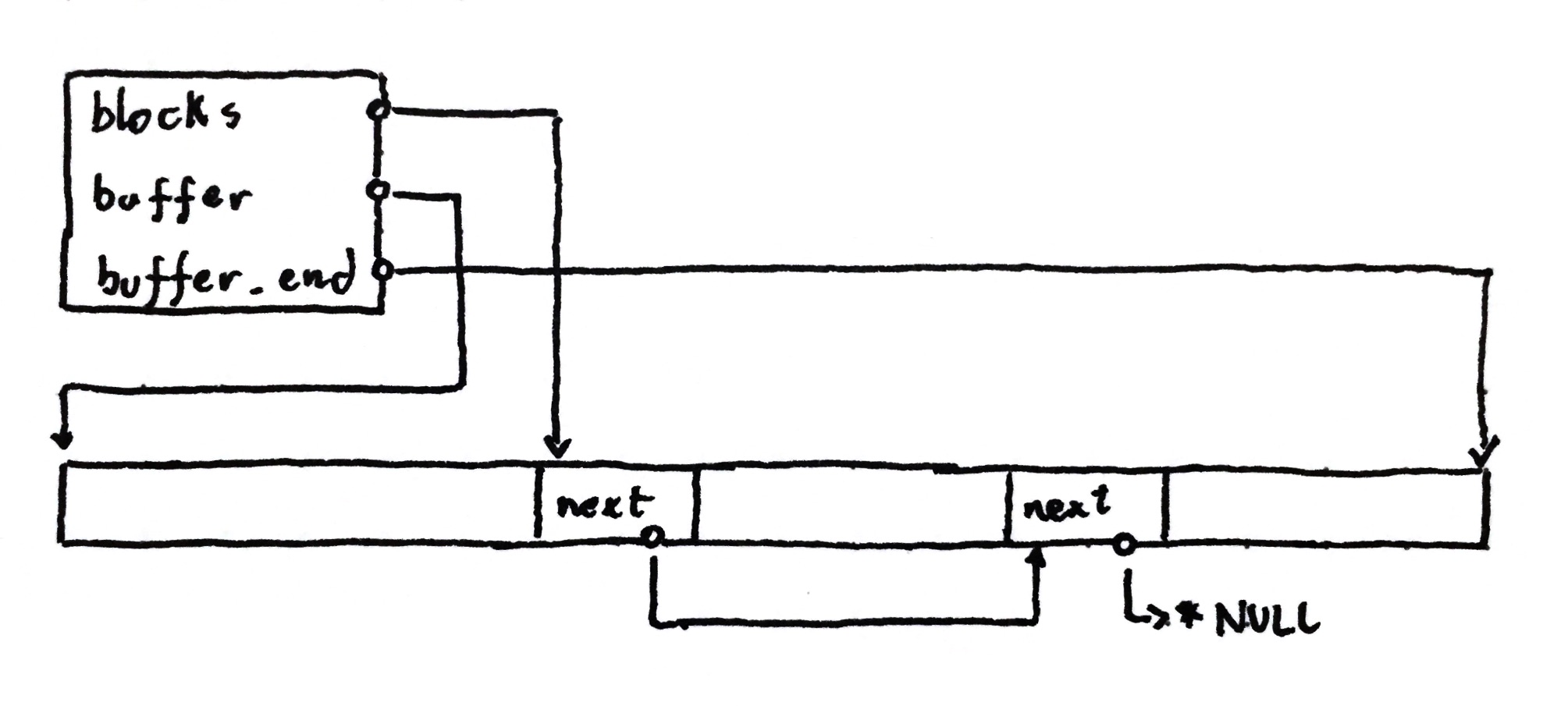
A block is basically an FBA in a linked-list. Whenever there is a request to allocate memory, we use the first block in the list to allocate it. If it is already full, then allocate a new block, prepend it to the list and use the new one going forward. In the end, when the time to free all the memory arrives, we walk the linked-list freeing each of the blocks.
But what about the weird uint8_t buffer[] member in the block? And what about
how the buffer intersects the struct in the example image?
Well, that is a special C trick called flexible array member, and it allows us
to reference memory past the end of the struct. Think about the memory layout of
the arena_block_t struct:

We see the three pointers of our struct: next, buffer_end and head. They
represent the real size of or struct, 24 bytes on a 64bit architecture. The
buffer[] field is compiler magic to point to the first byte after these 24.
This will probably make more sense with some code:
#define ARENA_BLOCK_SIZE 1024
static inline void arena_block_init(arena_block_t *b, arena_block_t *next) {
b->next = next;
// the end of the buffer is the size of the allocation. Another way to write this
// would be:
// b->buffer_end = b->buffer - sizeof(arena_block_t) + ARENA_BLOCK_SIZE;
b->buffer_end = ((uint8_t *)b) + ARENA_BLOCK_SIZE;
b->head = b->buffer;
}
static arena_block_t *arena_new_block(arena_t *a) {
arena_block_t *blk = malloc(ARENA_BLOCK_SIZE);
if (!blk) return NULL;
// initialize the block and prepend to the linked list
arena_block_init(blk, a->blocks);
a->blocks = blk;
return blk;
}
The block is allocated to the full size (1 KiB in this case), and not the size of
the struct. This matches the behavior explained above, the buffer is the memory
right after the struct. This also means that the space actually available for
allocation is 1000 bytes and not 1024, because of arena_block_t at the start
of the memory region.
Now moving on to the rest of the implementation:
// exaclty the same as fba_alloc_opt
static void *arena_block_alloc(arena_block_t *b, size_t size, size_t align) {
// get the head, aligned correctly and check if we have enough space
uint8_t *head = (uint8_t *)ALIGN_TO((uintptr_t)b->head, align);
if (head + size > b->buffer_end) {
return NULL;
}
// move the head forward and return
b->head = head + size;
return head;
}
static arena_block_t *arena_get_block(arena_t *a) {
if (a->blocks)
return a->blocks;
// allocate the first block in the list
return arena_new_block(a);
}
static void *arena_alloc(arena_t *a, size_t size, size_t align) {
arena_block_t *blk = arena_get_block(a);
if (!blk)
return NULL;
void *buf = arena_block_alloc(blk, size, align);
if (buf)
return buf;
blk = arena_new_block(a);
return arena_block_alloc(blk, size, align);
}
static void arena_clear(arena_t *a) {
arena_block_t *b = a->blocks;
while (b) {
arena_block_t *next = b->next;
free(b);
b = next;
}
a->blocks = NULL;
}
This is quite a bit more code than the previous one. It is, however, quite simple. Considering the following usage code:
int main(void) {
arena_t arena = {};
// 1
int *things = arena_alloc(&arena, sizeof(*things), _Alignof(*things));
// 2
things = arena_alloc(&arena, sizeof(*things) * 4, _Alignof(*things));
// 3
char *big = arena_alloc(&arena, 990, _Alignof(*big));
arena_clear(&arena);
return EXIT_SUCCESS;
}
The following sequence will take place for the first allocation:
arena_allocis called, it callsarena_get_block.arena_get_blockcheck ifblockshas items, it does not, so it callsarena_new_block.arena_new_blockallocates a memory region with sizeARENA_BLOCK_SIZEand initializes it. In the initialization we set thenextfield to the current start of the list (which isNULL), thebuffer_endto the end of the allocated region andheadto the start of the buffer. Finally, we set theblocksto the new block.- Back in
arena_alloc, we use the returned block to allocate withsizeandalign. arena_block_allocis identical tofba_alloc, and will succeed in this case (as the block is empty).
After the first allocation the state of our allocator is:
blocksis a linked-list with a single block in it.- The single block in our list has
sizeof(int)allocated in it.
In the second allocation:
arena_alloccallsarena_get_block, and as we have a block allocated, it returns it.arena_block_allocsucceeds, and we now havesizeof(int) * 5allocated in it.
In the third allocation:
arena_alloccallsarena_get_block, and as we have a block allocated, it returns it.arena_block_allocfails, so we allocate a new empty block and make it the head of our linked list. We then try to allocate from the new block, which succeeds.
This shows that when there is a great discrepancy in the sizes of allocations (some are huge and others tiny) the arena may waste quite a bit of memory. One very easy fix is to use more than one arena, each tuned to the kinds of allocations that it will be used for (this thought can be expanded to using one kind of allocator for each use case).
Optimizing the arena
Our arena is great, but there is one very big problem with it: it still uses malloc.
The blocks our arena uses are fixed size, but we go through all the functionality
and complexity of libc to get it. One way to fix this is to go directly to the OS
and map full pages at a time. On Linux, we have a syscall exactly for that: mmap.
From the man pages, it’s signature is:
void *mmap(void *addr, size_t len, int prot, int flags, int fildes, off_t off);
mmap can do a lot of things, but for our purposes all that we need is the
ability to allocate a full page of memory directly from the kernel. Now what is
the page size? Or even better, what is a page?
The operating system maps the physical memory of the computer into virtual memory. This is what allows magic such as hibernation, swap memory and, perhaps more critically, process isolation. Details and technicalities aside, a page is the minimum amount of memory that can be mapped by a process, and as such, the minimum that we will actually consume when requesting memory from the kernel. If we want our blocks to have the minimum amount of overhead as possible, they should have the same size as a page.
So, what is the page size? On most processors (virtual memory is implemented in hardware) pages are 4 KiB, or 4096 bytes. Why? I will leave the research to you (check this SO answer for some history). The fact is, there is a POSIX function that we can call to get the exact size in our system:
#include <stdio.h>
#include <unistd.h>
int main(void) {
long page_size = sysconf(_SC_PAGESIZE);
printf("page_size=%ld", page_size);
// stdout: page_size=4096
}
OK, we have the len parameter figured out. What about the rest? addr is the
desired start address for the memory region, we can pass NULL because we don’t
care. prot allows us to select what do we have permission to do with the data,
in this case we want PROT_READ | PROT_WRITE. flags is for configuring the
allocation, for our purposes, this will be MAP_ANONYMOUS, which means that the
allocation is not backed by a file, and MAP_PRIVATE because only the current
process should see it. fildes is the backing file descriptor when mapping a
file, which we are not doing, so we set this to -1. off is the offset from
which to start mapping, that we don’t care about, so 0.
In the end, to allocate a page for our arena we do:
#define ARENA_BLOCK_SIZE 4096
arena_block_t *blk = mmap(NULL, ARENA_BLOCK_SIZE, PROT_READ | PROT_WRITE,
MAP_ANONYMOUS | MAP_PRIVATE, -1, 0);
if (blk == MAP_FAILED)
return NULL;
And later, don’t forget, we need to free each page. We can do that by calling
mumap on each one:
munmap(b, ARENA_BLOCK_SIZE);
And that is all that was needed to get rid of malloc!
Block Allocators
The linear allocators are fine, but sometimes you want more control over when
memory gets freed. Going back to our HTTP server example, there is a lot of data
that we can free all at once at the end of the request lifecycle, that is the
perfect use-case for an arena. There is, however, data that can’t be allocated
inside the arena, the arena_t itself is one of them!
In our fictitious HTTP server, each request has a control struct with the socket, origin address, an arena for temporary allocations and some more metadata. This struct is allocated and freed very frequently, so we want this operation to be fast. Considering that all allocations will always have the same size, this is the perfect candidate for using a pool or block allocator.
This allocator allows fixed sized blocks to be allocated and freed in constant time. The disadvantage: there will be a predefined limit on the number of blocks. If we decide that we want 50 blocks, that is the maximum that we will get at any point.
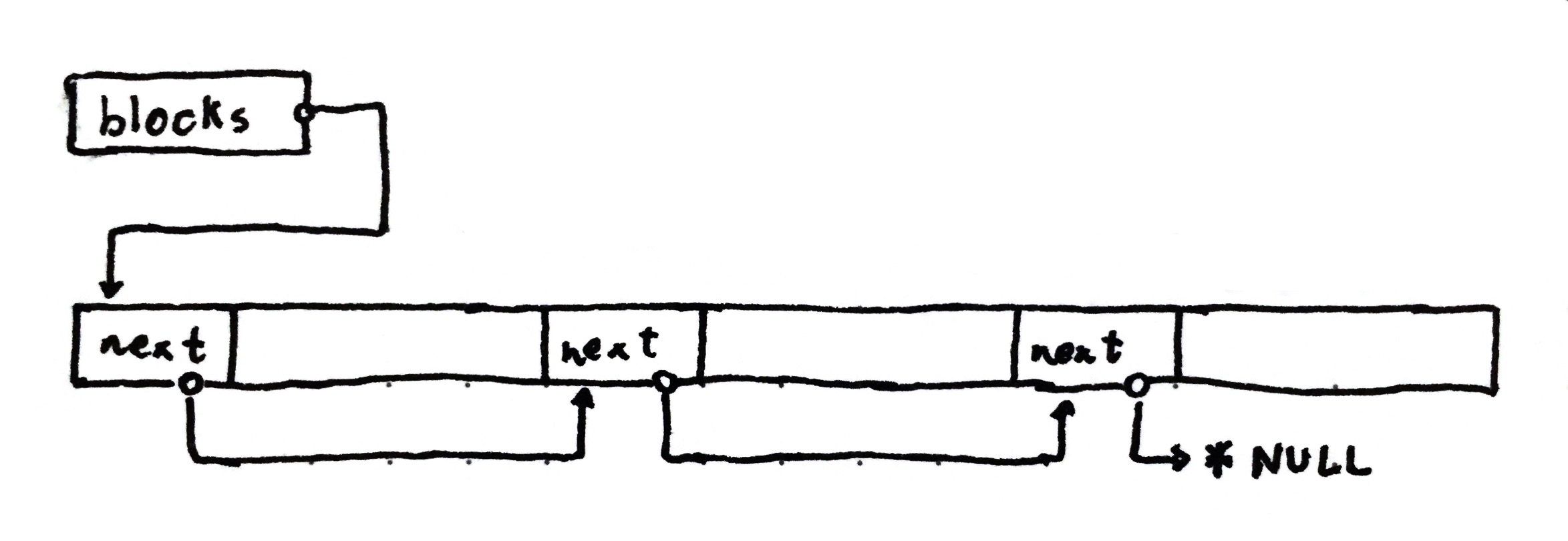
When the allocator is initialized we give it a buffer (just like the FBA), and then partition it based on the element size. Each block is initialized to have a pointer to the next one in the chain, so that we have a linked list.
When an allocation request arrives, we remove the first item in the list and return it to the user. This way our list only holds allocated items.
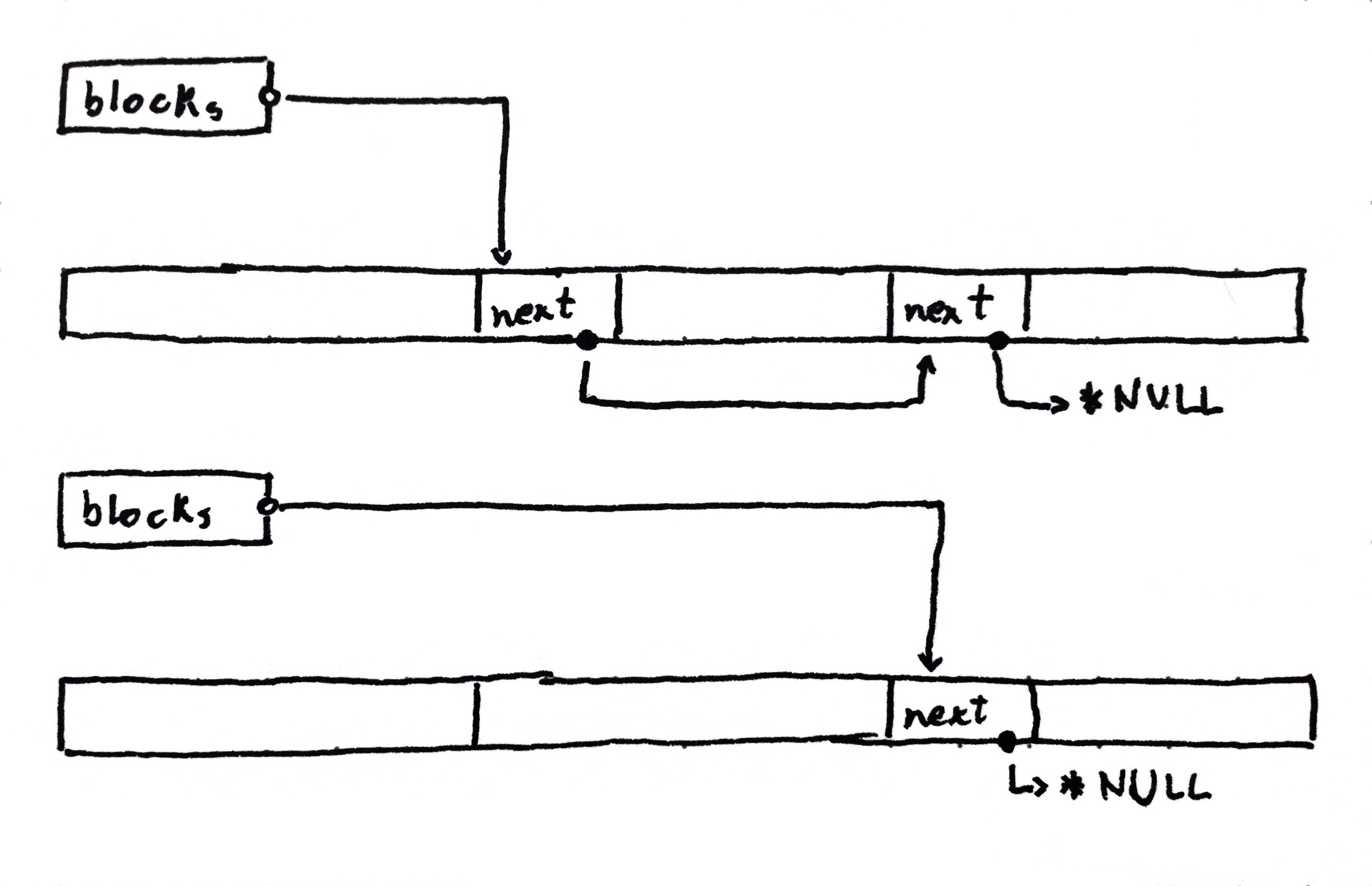
When the block is allocated there is no need to track it, the user should free
it at some point, then we get it back. This means that we can reuse the space
where the next pointer is when we return the block to the user. No wasted space!
When it is time to free the block, we simply add it back to the list. This is
where we could stop, but I also decided to add pointers to the start and end of
the buffer for safety. With this extra data it is possible to validate that the
pointer given to free is indeed managed by the block allocator (i.e. it is
contained in the backing buffer). In the example, we free the second block:
One thing you might notice is that (although not in this example) the blocks lose their ordering very quickly. This is not a problem, as we still just return the first one in the list. If anything, this makes it faster, as the returned block is the most recently used one.
Now onto some code:
#include <assert.h>
#include <stddef.h>
#include <stdint.h>
#include <string.h>
typedef struct block_allocator_block {
struct block_allocator_block *next;
} block_allocator_block_t;
typedef struct block_allocator {
uint8_t *buffer;
uint8_t *buffer_end;
block_allocator_block_t *blocks;
} block_allocator_t;
static void ba_init(block_allocator_t *ba, uint8_t *buffer, size_t buffer_size,
size_t item_size) {
assert(item_size >= sizeof(block_allocator_block_t));
size_t item_count = buffer_size / item_size;
// initialize all of the blocks, this creates a linked list of free blocks
block_allocator_block_t *prev = NULL;
for (size_t i = 0; i < item_count; i++) {
block_allocator_block_t *b =
(block_allocator_block_t *)(buffer + i * item_size);
*b = (block_allocator_block_t){.next = prev};
prev = b;
}
ba->buffer = buffer;
ba->buffer_end = buffer + buffer_size;
ba->blocks = prev;
}
static void *ba_alloc(block_allocator_t *ba) {
if (!ba->blocks)
return NULL;
block_allocator_block_t *blk = ba->blocks;
ba->blocks = blk->next;
// clear at least the reference to the next block before returning
memset(blk, 0, sizeof(block_allocator_block_t));
return blk;
}
static void ba_free(block_allocator_t *ba, void *ptr) {
uint8_t *p = ptr;
// don't put in our list pointers that are not in our buffer
if (p < ba->buffer || p > ba->buffer_end)
return;
block_allocator_block_t *blk = ptr;
*blk = (block_allocator_block_t){.next = ba->blocks};
ba->blocks = blk;
}
// --- Example:
typedef struct item {
char name[32];
int socket;
} item_t;
int main() {
static uint8_t buffer[4096];
block_allocator_t alloc;
ba_init(&alloc, buffer, sizeof(buffer), sizeof(item_t));
item_t *item0 = ba_alloc(&alloc);
printf("item0=%p\n", item0);
// item0=0x58773c9b1020
item_t *item1 = ba_alloc(&alloc);
printf("item1=%p\n", item1);
// item1=0x58773c9b0ffc
ba_free(&alloc, item0);
item_t *item2 = ba_alloc(&alloc);
printf("item0=%p, item2=%p\n", item0, item2);
// item0=0x58773c9b1020, item2=0x58773c9b1020
return EXIT_SUCCESS;
}
It is a direct translation of what was explained above. The ba_alloc function
pops the first item of the list and the ba_free function puts it back (ignoring
any pointer that has not originated from our buffer). This allocator also has the
same characteristics of the ones before (FBA and arena), it is possible to free
all allocations at once:
// the block allocator does not store the size of the items, so we need to pass
// it on the reset.
ba_reset(ba, ba->buffer, ba->buffer_end - ba->buffer, item_size);
One thing you might also notice that the block allocator can be extended in much the same way as our fixed buffer allocator. By moving the buffer management into the allocator, we get the ability to allocate more on demand. That, however, I will leave as an exercise to the reader.
Conclusion
I hope that this post opens your eyes to the world of allocators, and how it changes our perspective on memory management. There are other types of allocators (oh, there are so many more), but this was an introduction to the ones that might help the most to have in your tool belt.